
Mọi bot thu thập dữ liệu của công cụ tìm kiếm trước tiên đều tương tác với tệp robots.txt của trang web và các quy tắc thu thập dữ liệu của trang web đó. Điều này có nghĩa là tệp robots.txt đóng vai trò then chốt trong quá trình tối ưu hóa công cụ tìm kiếm (SEO) của blog Blogger. Bài viết này sẽ hướng dẫn bạn cách tạo tệp robots.txt tùy chỉnh được tối ưu hóa tốt cho Blogger và cách hiểu tác động của các trang bị chặn do Google Search Console báo cáo.
Chức năng của tệp robots.txt là gì?
Tệp robots.txt cho công cụ tìm kiếm biết trang nào nên và không nên thu thập dữ liệu. Điều này cho phép chúng tôi kiểm soát việc thu thập dữ liệu của tất cả các con nhện trên mạng. Trong tệp robots.txt, chúng tôi có thể kiểm soát hoạt động thu thập thông tin của từng tác nhân người dùng bằng cách cho phép hoặc không cho phép chúng. Chúng tôi cũng có thể khai báo sơ đồ trang web của trang web của mình cho các công cụ tìm kiếm như Google, Bing, Yandex, v.v. Để các công cụ tìm kiếm này có thể dễ dàng tìm thấy và lập chỉ mục nội dung của chúng tôi.

Chức năng của thẻ meta robot là kiểm soát chỉ mục cấp trang hoặc noindex
Thông thường, chúng tôi sử dụng thẻ meta rô-bốt để lập chỉ mục hoặc lập chỉ mục các bài đăng và trang blog trên toàn bộ trang web. Và robots.txt để điều khiển các bot công cụ tìm kiếm. Bạn có thể cho phép thu thập dữ liệu toàn bộ trang web, nhưng việc này sẽ làm cạn kiệt ngân sách thu thập dữ liệu của trang web. Để tiết kiệm ngân sách thu thập dữ liệu của trang web, bạn phải chặn các phần tìm kiếm, lưu trữ và nhãn của trang web.
Thẻ meta robot ở cấp độ trang và được sử dụng để quyết định xem công cụ tìm kiếm nên hiển thị hay ẩn các bài đăng và trang blog trên internet. Ngoài ra, một tệp có tên robots.txt giúp kiểm soát cách hoạt động của các bot công cụ tìm kiếm trên trang web. Nếu chúng ta để các bot tự do thu thập thông tin trên toàn bộ trang web của mình, nó có thể sử dụng rất nhiều tài nguyên. Để quản lý việc này, chúng tôi có thể sử dụng robots.txt để yêu cầu các bot không thu thập dữ liệu một số phần nhất định, như phần tìm kiếm, lưu trữ và gắn nhãn. Bằng cách này, chúng tôi tiết kiệm tài nguyên và đảm bảo các bot tập trung vào nội dung quan trọng trên trang web của chúng tôi.
Tệp Robots.txt mặc định của Blog Blogger.
Để tối ưu hóa tệp robots.txt cho blog Blogger, trước tiên chúng ta cần hiểu cấu trúc CMS và phân tích tệp robots.txt mặc định. Tệp robots.txt mặc định của Blogger-
User-agent: Mediapartners-Google
Disallow:
User-agent: *
Disallow: /search
Allow: /
Sitemap: https://www.example.com/sitemap.xml- Dòng đầu tiên (User-Agent) của tệp này khai báo loại bot. Đây là Google AdSense, không được phép sử dụng (được khai báo ở dòng thứ 2). Điều đó có nghĩa là quảng cáo AdSense có thể xuất hiện trên toàn bộ trang web.
- Tác nhân người dùng sau đây là *, có nghĩa là tất cả các bot công cụ tìm kiếm không được phép vào các trang /tìm kiếm. Điều đó có nghĩa là không cho phép tất cả các trang tìm kiếm và nhãn (cùng cấu trúc URL).
- Và thẻ cho phép xác định rằng tất cả các trang ngoài phần không cho phép đều có thể được thu thập thông tin.
- Dòng sau đây chứa sơ đồ trang web đăng bài cho blog Blogger.
Đây là một tệp gần như hoàn hảo để điều khiển các bot công cụ tìm kiếm và cung cấp hướng dẫn cho các trang thu thập dữ liệu hoặc không thu thập dữ liệu. Nhưng tệp này cho phép lập chỉ mục các trang lưu trữ, điều này có thể gây ra sự cố trùng lặp nội dung. Điều đó có nghĩa là nó sẽ tạo rác cho blog của Blogger.
Tối ưu hóa tệp Robots.txt cho blog Blogger
Chúng tôi đã hiểu cách tệp robots.txt mặc định thực hiện chức năng của nó đối với blog Blogger. Hãy tối ưu hóa nó để SEO tốt nhất.
Tệp robots.txt mặc định cho phép kho lưu trữ lập chỉ mục, điều này gây ra sự cố trùng lặp nội dung. Chúng tôi có thể ngăn chặn sự cố này bằng cách ngăn bot thu thập dữ liệu phần lưu trữ. Đối với điều này, /search* sẽ vô hiệu hóa việc thu thập thông tin của tất cả các trang tìm kiếm và nhãn.
Việc áp dụng quy tắc Không cho phép /20* vào tệp robots.txt sẽ ngừng thu thập thông tin các phần lưu trữ. Quy tắc /20* sẽ chặn việc thu thập dữ liệu của tất cả các bài đăng, vì vậy để tránh điều này, chúng tôi phải áp dụng quy tắc Cho phép mới cho phần /*.html cho phép bot thu thập dữ liệu các bài đăng và trang.
Sơ đồ trang web mặc định bao gồm các bài đăng, không phải các trang. Vì vậy, bạn phải thêm sơ đồ trang web cho các trang nằm trong https://example.blogspot.com/sitemap-pages.xml hoặc https://www.example.com/sitemap-pages.xml cho miền tùy chỉnh. Bạn có thể gửi sơ đồ trang web Blogger tới Google Search Console để có kết quả tốt.
Vì vậy, tệp robots.txt tùy chỉnh hoàn hảo mới cho blog Blogger sẽ trông như thế này.
User-agent: Mediapartners-Google
Disallow:
User-agent: * # to select all crawling bots and search engines
Disallow: /search* # to block all user generated query item within the website.
Disallow: /20* # this line will disallow archieve section of Blogger.
Disallow: /feeds* # this line will disallow feeds. Read instruction below
Allow: /*.html # allow all post and pages of the blog
#sitemap of the blog
Sitemap: https://www.example.com/sitemap.xml
Sitemap: https://www.example.com/sitemap-pages.xml- /search* sẽ vô hiệu hóa việc thu thập thông tin của tất cả các trang tìm kiếm và nhãn.
- Áp dụng quy tắc Không cho phép /20* vào tệp robots.txt để dừng thu thập thông tin các phần lưu trữ.
- Không cho phép: /feeds* quy tắc này sẽ không cho phép trình thu thập thông tin thu thập dữ liệu phần nguồn cấp dữ liệu. Nhưng nếu bạn chưa tạo sơ đồ trang XML Blogger mới thì đừng sử dụng dòng này.
- Quy tắc /20* sẽ chặn việc thu thập dữ liệu của tất cả các bài đăng. Vì vậy, để tránh điều này, chúng tôi phải áp dụng quy tắc Cho phép mới cho phần /*.html cho phép bot thu thập dữ liệu các bài đăng và trang.
Bạn phải thay thế www.example.com bằng tên miền Blogger hoặc tên miền tùy chỉnh của bạn. Ví dụ: giả sử tên miền tùy chỉnh của bạn là www.iashindu.com; thì sơ đồ trang web sẽ có tại https://www.iashindu.com/sitemap.xml. Ngoài ra, bạn có thể kiểm tra robots.txt hiện tại tại https://www.example.com/robots.txt.
Trong tệp trên, cài đặt này là cách thực hành tốt nhất trong robots.txt cho SEO. Điều này sẽ tiết kiệm ngân sách thu thập dữ liệu của trang web và giúp blog Blogger xuất hiện trong kết quả tìm kiếm. Bạn phải viết nội dung thân thiện với SEO để xuất hiện trong kết quả tìm kiếm.
Hiệu ứng trong Search Engine Console sau khi triển khai các quy tắc này trong robots.txt
Điều quan trọng cần lưu ý là Google Search Console có thể báo cáo rằng một số trang bị tệp robots.txt của bạn chặn. Tuy nhiên, điều quan trọng là phải kiểm tra xem trang nào bị chặn. Chúng là trang nội dung hay trang tìm kiếm hoặc lưu trữ? Chúng tôi không thể hiển thị các trang tìm kiếm và lưu trữ, đó là lý do tại sao các trang này bị chặn.
Nhưng nếu bạn muốn cho phép bot thu thập dữ liệu toàn bộ trang web thì bạn phải định cấu hình thẻ meta robot và tệp robots.txt theo cách đó.
- Tệp Robots.txt cho phép trình thu thập thông tin thu thập dữ liệu toàn bộ trang web.
- Thẻ Meta robot không cho phép các trang không quan trọng lọt vào danh mục noindex.
Việc kết hợp các thẻ meta robots.txt và robots.txt của Blogger có thể làm cạn kiệt ngân sách thu thập dữ liệu, nhưng giải pháp thay thế tốt hơn là tăng cường SEO cho blog Blogger.
Bạn triển khai Tệp Robots.txt này cho Blogger bằng cách nào?
Tệp Robots.txt nằm ở cấp độ gốc của trang web. Không có quyền truy cập vào thư mục gốc trong Blogger, vậy làm cách nào để chỉnh sửa tệp robots.txt này? Bạn có thể truy cập các tệp gốc như robots.txt trong phần cài đặt của Blogger.
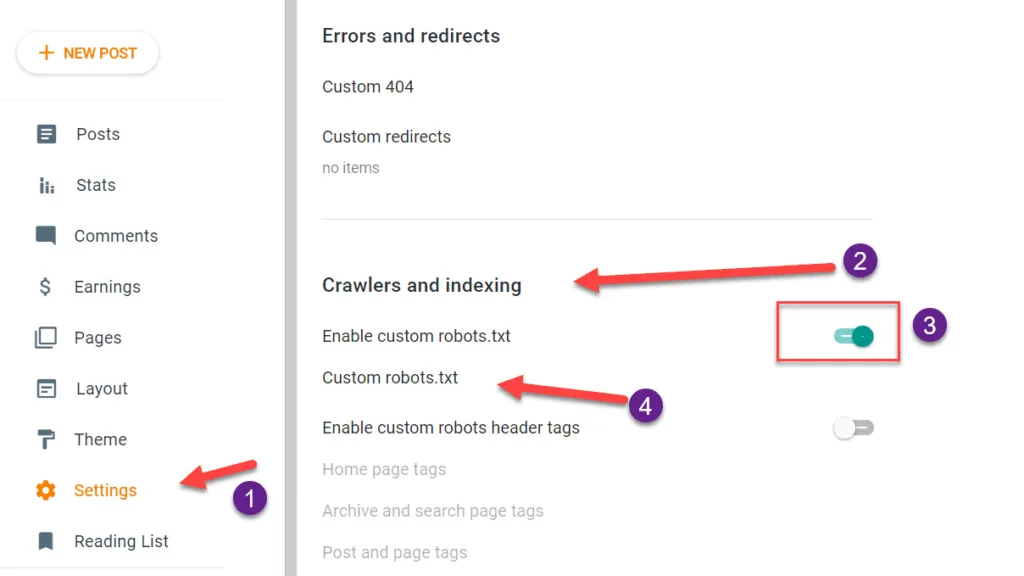
- Đi tới Bảng điều khiển Blogger và nhấp vào tùy chọn cài đặt,
- Cuộn xuống phần thu thập thông tin và lập chỉ mục,
- Bật robots.txt tùy chỉnh bằng nút chuyển đổi.
- Nhấp vào robots.txt tùy chỉnh; một cửa sổ sẽ mở ra. Dán tệp robots.txt và cập nhật.
Sau khi cập nhật tệp robots.txt tùy chỉnh cho blog Blogger, bạn có thể kiểm tra các thay đổi bằng cách truy cập miền của mình như https://www.example.com/robots.txt, trong đó www.example.com sẽ được thay thế bằng địa chỉ miền của bạn .
Kết luận.
Chúng tôi đã khám phá chức năng của tệp robots.txt và tạo tệp robots.txt tùy chỉnh tối ưu cho blog Blogger. Trong tệp robots.txt mặc định, phần lưu trữ cũng được phép thu thập thông tin, điều này gây ra sự cố trùng lặp nội dung cho công cụ tìm kiếm. Sự nhầm lẫn này có thể dẫn đến việc Google không xem xét bất kỳ Trang nào cho kết quả tìm kiếm.
Hãy nhớ rằng Google Search Console có thể báo cáo các trang bị chặn nhưng điều quan trọng là phải hiểu trang nào bị chặn và tại sao. Sự hiểu biết này sẽ giúp bạn tối ưu hóa trang web của mình để có kết quả SEO tốt hơn.
Tôi hy vọng bạn thấy bài viết này hữu ích. Nếu bạn có bất kỳ nghi ngờ hoặc câu hỏi nào liên quan đến Blogger hoặc WordPress SEO, vui lòng bình luận bên dưới.






Trả lời
Bạn phải đăng nhập để gửi bình luận.