Bạn đã tạo một trang web và công cụ tìm kiếm có thể thu thập dữ liệu trang web đó. Nhưng nếu bạn không muốn công cụ tìm kiếm thu thập dữ liệu một số phần của trang web thì sao? Làm cách nào bạn có thể chặn các phần đó của trang web đối với công cụ tìm kiếm? Tệp robots.txt.
Vì vậy, bạn muốn hiểu tệp robots.txt? Nhưng nếu tôi nói đó là trình kiểm tra đường dẫn bot đang bò. Điều đó cho phép hoặc không cho phép bot trên một số con đường và chặn những con đường khác. Tệp này cho phép hoặc không cho phép các bot công cụ tìm kiếm thu thập dữ liệu một số phần trên trang web của bạn và không cho phép các phần khác.
Hiểu tệp robots.txt của một trang web. Nó là gì và nó thực hiện những chức năng gì?
Tối ưu hóa Công cụ Tìm kiếm và Robots.txt
Bot công cụ tìm kiếm là gì?: Đây là những bot đọc dữ liệu từ một trang web hoặc trang web và chuyển dữ liệu đó đến cơ sở dữ liệu của chúng như Google, Bing, Yandex hoặc bất kỳ trang nào khác. Ví dụ: giả sử bạn tạo một trang web và liên tục viết bài trên đó.
Backlink nội bộ và robots.txt: Nếu bạn đang viết một bài viết và trong đó, bạn cung cấp một số liên kết nội bộ có thể thuộc danh mục hoặc nhãn hoặc bất kỳ thứ gì khác bị robots.txt chặn. Bây giờ, liên kết mà bạn cung cấp trong bài viết sẽ đi theo vì nó là nội bộ, đồng thời, bạn không cho phép liên kết đó theo quyền được đặt trong tệp robots.txt. Vì vậy, cách tốt nhất đối với các trang nội bộ không nên lập chỉ mục nhưng thu thập dữ liệu là noindex các trang đó, không cho phép sử dụng tệp robots.txt.
Tệp robots.txt nên chặn những trang nào: Tệp này sẽ chặn các trang nhạy cảm. Đó có thể là phần quản trị của trang web hoặc blog của bạn. Tất cả các trang khác gây ra nội dung rác hoặc nội dung kép phải được noindex bằng cách sử dụng thẻ meta hoặc thẻ x-robots thích hợp.
Các liên kết từ các tài nguyên bên ngoài sẽ chặn: Giả sử ai đó đã cung cấp một liên kết ngược của trang web của bạn thuộc phần danh mục, thì trong trường hợp đó, công cụ thu thập thông tin sẽ cố gắng thu thập dữ liệu trang web của bạn nhưng robots.txt chặn nó thu thập dữ liệu và một liên kết ngược khó kiếm được sẽ bị lãng phí.
Cú pháp robots.txt được sử dụng
Đại lý người dùng:
Điều này khai báo các bot hoặc trình thu thập dữ liệu web mà chúng tôi đang hướng dẫn hoặc kiểm soát chúng cho các phần khác nhau bằng cách sử dụng chức năng cho phép và không cho phép.
Không cho phép:
Bạn có thể khai báo các phần trang không được công cụ tìm kiếm thu thập dữ liệu. Sử dụng phương pháp này, chúng tôi có thể lưu hạn ngạch thu thập dữ liệu của công cụ tìm kiếm dành riêng cho trang web của chúng tôi.
Cho phép:
Nó thường được sử dụng cho Googlebot để cho phép các phần thu thập dữ liệu của trang web. Ví dụ: nó có thể cho phép thư mục con mà thư mục mẹ không được phép thu thập thông tin.
Sitemap:
Nó khai báo vị trí hoặc blog của sơ đồ trang web XML—các công cụ tìm kiếm như Google, Bing, Yandex hỗ trợ lệnh này.
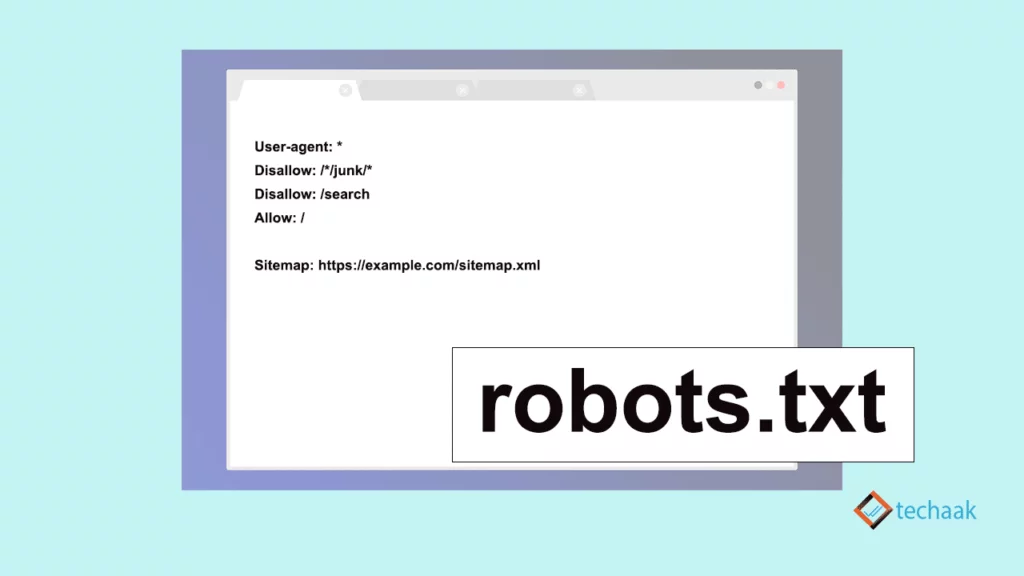
ví dụ về tệp robots.txt:
User-agent: Mediapartners-Google
Disallow:
User-agent: *
Disallow: /*/junk/*
Disallow: /search
Allow: /
Sitemap: https://example.com/sitemap.xmlTrong ví dụ về robots.txt ở trên
- Tác nhân người dùng: Mediapartners-Google tuyên bố hướng dẫn dành cho Google AdSense, hướng dẫn được tuân theo là Không cho phép: không có gì. Điều đó có nghĩa là AdSense có thể thu thập dữ liệu toàn bộ trang web của bạn và hiển thị quảng cáo.
- Liên kết lệnh tiếp theo là Tác nhân người dùng: *, trong đó nghĩa là hướng dẫn dành cho tất cả các bot hoặc trình thu thập thông tin khác ngoài Google AdSense.
- Không cho phép: /*/junk/* và Không cho phép: /tìm kiếm không cho phép thư mục con “rác” vào bất kỳ thư mục mẹ nào. Và cả thư mục mẹ “tìm kiếm”. Lệnh cho phép cho phép toàn bộ trang web thu thập dữ liệu. Bạn có thể bao gồm các phần riêng tư của trang web không được lập chỉ mục trong kết quả tìm kiếm.
- Sitemap: https://example.com/sitemap.xml là vị trí của sơ đồ trang web được thêm vào miền.
Kiểm tra cách bạn có thể thiết lập nó cho WordPress và Blogger.
Tôi có thể đặt tệp robots.txt ở bất kỳ đâu trên trang web của mình không?
Không, tệp robots.txt luôn nằm trong thư mục gốc có tên robots.txt. Và bạn thậm chí không thể thay đổi tên của nó.
Tôi có thể cung cấp nhiều sơ đồ trang web trong tệp robots.txt không?
Có, Bạn có thể cung cấp nhiều sơ đồ trang web trong tệp robots.txt.
Tôi có thể sử dụng tệp robots.txt để xóa một trang khỏi công cụ tìm kiếm không?
Không, để làm được điều đó, bạn phải sử dụng thẻ meta robots hoặc X-Robots-Tag trong phản hồi tiêu đề.






Trả lời
Bạn phải đăng nhập để gửi bình luận.